Drilling Deeper Into Our State Surveys
By the Alliance of Automobile Manufacturers and the Entertainment Software Association
With the luxury of a little more time since Election Day, we’ve taken a closer look at how we did pollwise relative to 538, RealClearPolitics and Huffington.
To refresh your memory, the Alliance of Automobile Manufacturers, in partnership with the Entertainment Software Association, tracked the presidential and Senate races in six states for weeks leading up to the election. The states were chosen because they were significant to the presidential contest and/or were relevant to determining party control of the Senate. We contracted with Pulse Opinion Research to execute the research with a combination of automated calling technology and the internet. Collecting the data five nights a week – 175 completed surveys per evening per state - we ran the numbers through three different turnout models. For the last two nights of research, we doubled the number of completed surveys. Each week, Monday through Friday, we reported three-day and five-day results for each of the three turnout models, thus generating six different outcomes daily.
As expected, since it utilized a larger sample size, the longer roll was a more stable – and in the end slightly more accurate – measure. But we wanted to show the three-day average as well to better capture late- breaking movement. The combination of the two provided useful intelligence to better understand whether a race was stable or shifting.Our baseline turnout model for each state – the “Expected” turnout – was predicated on POR’s demographic weighting that was constructed using past history and other analytic procedures. We also looked at other public surveys to assess our weighting and made some further adjustments in limited circumstances. Our “Strong Democrat” turnout was based on the 2012 presidential election, though we did not further inflate minority turnout despite the ongoing demographic changes than might have warranted that decision. Finally, our “Strong Republican” turnout was based largely on 2014, but modified slightly to reflect whether that state had a high turnout in 2014 (such as in Florida) or a relatively low turnout in 2014 (such as in Ohio). Creating the models was a bit like salting a stew – part science and part feel. But by using different models, we didn’t bias the analysis with our own turnout expectations.
After the election, we compared our results in the six states (Florida, Ohio, North Carolina, Pennsylvania, New Hampshire and Nevada) to the RealClearPolitics (RCP) average, the Huffington Post Pollster and Nate Silver’s 538 Projection. We looked at the following measures:
- Average Delta, reflecting the average difference between the projection and the outcome.
- Correct Picks, reflecting the number of races for which the winner was accurately projected.
- Close Picks, reflecting the number of races for which the analysis was within two points of the outcome.
Here’s what we found...
The 5-day Alliance/ESA track weighted for “Strong Republican” turnout was, by far, the most accurate model. Of the nine models evaluated (our six plus RCP, Huffington and 538), it had the closestThe second most accurate model was the 3-day Alliance/ESA weighted for “Strong Republican” turnout, which came in first twice and second six times.
The next two most accurate models were the 3-day and 5-day Alliance/ESA “Expected Turnout” models. The 3-day came in first twice and second twice while the 5-day came in first once and second once.
RCP had no firsts and one second.Huffington was skunked.
538 was skunked.
And both our 3-day and 5-day “Strong Democrat” models were skunked as well. The “Strong Democrat” models ranked eight and ninth of all those compared.
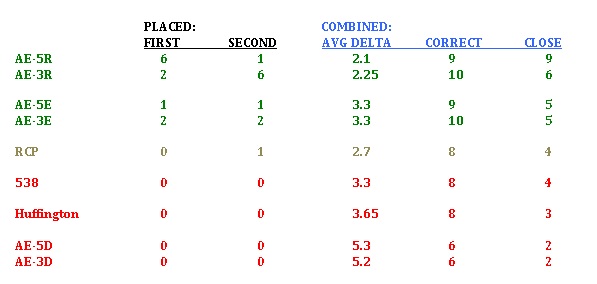
Below is the scorecard. The first two columns show how many times each model was best or second best (note there were some ties). The following three columns – in blue – compare performance.
So what did we learn from this?
-
The 5-day Alliance/ESA with “Strong Republican” turnout clearly was the strongest predictor. It had the lowest combined
average delta from final outcome (2.1), it had the highest number of projections within two points (9 of 12) and it was correct in 9 of the 12 races tested (just behind the 3-day “Strong Republican” and “Expected” models which both were at 10 correct predictions).The 3-day Alliance/ESA “Strong Republican” model came in second overall. Both “Expected” turnout models were solid and arguably as good or better than the aggregators. The 3-day Alliance/ESA Strong Republican and Expected models both performed best by predicting 10 of the 12 outcomes. The Alliance/ESA “Strong Democrat” models performed poorly.
- The RCP average was the best of the aggregation options, especially as measured by
average delta . - 538 and Huffington were weak constructs that biased conventional wisdom within the Beltway and beyond and helped create a distorted expectation about what election day would yield, both about who would win the presidency and which party would control the Senate. Detailed quantification can falsely imply precision; it did so here.
- The concept of showing alternative turnout models is a superior way to communicate what is going on in a race – when compared to various techniques of aggregation - by focusing attention on the factor that is most critical to accurately projecting the outcome. By definition, aggregation tools combine surveys with different collection techniques, different weighting estimates, different sample sizes and different levels of underlying expertise. When we say the polls were wrong, in effect we are combining a series of error factors, blending them, and then saying the composite was inaccurate. The conclusion is wrong in that the polls were not, per se, inaccurate. And the implication is wrong; to the extent there was polling error, it was probably dominantly caused by turnout estimation failures – the fault of human subjectivity rather than scientific objectivity.
- Looking at just the Alliance/ESA data, we saw that the “Expected” turnout model beat the “Republican” turnout model in two states where there was higher Hispanic participation, suggesting that the somewhat organic Republican surge witnessed around the country was mitigated by the Hispanic-specific turnout effort by the Democrats.
- Again, looking at just the Alliance/ESA data, we saw two different patterns in these races. One pattern was pure stability, where the race fundamentally did not change over the ten days and the variations we saw in outcomes looked very much like statistical noise rather than real movement between the candidates. This seemed particularly true in the Florida and Nevada senate races, where if you took the midpoint or the average of the last ten days, you were pretty much spot on predicting the outcome (utilizing the right model). The other pattern was movement, and that was evident in the Pennsylvania race, where you could see Toomey’s progression from near certain defeat to improbable victory.
- Given that perhaps the hardest thing to figure out is whether movement in a race is noise (bouncing around the margin of error) or a genuine shift in preference, the best approach to analyze the distinction is to examine a variety of inputs. Look at the range of polls. Look at the midpoint. Look at timing of those polls (how recently in the field) and if they are tracks, how many days they reflect. If the band is consistent over a period of time and narrowing, you have a decent sense that the race is stable and predictable. If the band is erratic or widening, not so much.
- The polls work reasonably well, even without live callers. The challenge is less the accuracy of the polls, or finding the right folks to fill in the sample, than knowing who is showing up. That is the variable we all must focus on with more diligence and care, and that factor, as noted before, is part objective and part subjective. We know the demographic pattern and changes in share of the electorate. And we can get measures of voter certainty and enthusiasm. We can then throw in some logic – immeasurable as it might be – to adjust our turnout expectations. Get turnout right, and you’ve got things pretty well figured out as the polls will likely lead you to the right conclusion.
For two cycles in a row, partisans were either surprised or shocked by the results. Republicans in 2012 and Democrats in 2016 were guilty of essentially the same fault, and that was making inaccurate assumptions about turnout. When the unexpected outcome happened, many blamed polls rather than a human tendency to see what they wanted to see.
In 2012, four years removed from Bush fatigue, Republicans simply wanted to believe that the Obama turnout of 2008 would not replicate itself. How could it, reasoned the GOP, when 2008 was fueled by an intense desire for change and the unbridled promise of a new leader – while 2012 – on the heels of a massive 2010 midterm win for Republicans – was a cycle in which reality had supplanted hope. So too, in 2016, Democrats derived confidence from an increasingly non-white electorate that would strengthen an already impenetrable blue wall. Throw in an anticipated decline in Republican support for Trump, and there was no way he would be able to compensate with new voters or a higher share of the white vote.
But the partisans were wrong. The polls were not wrong. They were, however, misapplied to reflect what people expected to occur rather than what was happening in real America.
Pulse Opinion Research conducts the field work and provides the methodology for all Rasmussen Reports surveys. Pulse did the state tracking surveys during the presidential election season for the Alliance of Automobile Manufacturers and the Entertainment Software Association.
Rasmussen Reports is a media company specializing in the collection, publication and distribution of public opinion information.
We conduct public opinion polls on a variety of topics to inform our audience on events in the news and other topics of interest. To ensure editorial control and independence, we pay for the polls ourselves and generate revenue through the sale of subscriptions, sponsorships, and advertising. Nightly polling on politics, business and lifestyle topics provides the content to update the Rasmussen Reports web site many times each day. If it's in the news, it's in our polls. Additionally, the data drives a daily update newsletter and various media outlets across the country.
Some information, including the Rasmussen Reports daily Presidential Tracking Poll and commentaries are available for free to the general public. Subscriptions are available for $4.95 a month or 34.95 a year that provide subscribers with exclusive access to more than 20 stories per week on upcoming elections, consumer confidence, and issues that affect us all. For those who are really into the numbers, Platinum Members can review demographic crosstabs and a full history of our data.
To learn more about our methodology, click here.